A Follow Up -- Explicit Error Bounds
05 Jan 2022 - Tags: quick-analysis-tricks , sage
In my previous post I talked about how we can use probability theory to make certain scary looking limits obvious. I mentioned that I would be writing a follow up post actually doing one of the derivations formally, and for once in my life I’m going to get to it quickly! Since I still consider myself a bit of a computer scientist, it’s important to know the rate at which limits converge, and so we’ll keep track of our error bounds throughout the computation. Let’s get to it!
Let $f : \mathbb{R} \to \mathbb{R}$ be bounded and locally lipschitz. Then for every $x \gt 0$,
\(\displaystyle e^{-nx} \sum_{k=0}^\infty \frac{(nx)^k}{k!} f \left ( \frac{k}{n} \right ) = f(x) \pm \widetilde{O}_x \left ( \frac{1}{\sqrt{n}} \right )\)
$\ulcorner$
In the interest of exposition, I’ll show far more detail than I think is required for the problem. Hopefully this shows how you might come up with each step yourself.
Let $X_n$ be poisson with parameter $nx$. Then notice
\[e^{-nx} \sum_{k=0}^\infty \frac{(nx)^k}{k!} f \left ( \frac{k}{n} \right ) = \mathbb{E} \left [ f \left ( \frac{X_n}{n} \right ) \right ]\]Now we compute
\[\begin{align} \left | \mathbb{E} \left [ f \left ( \frac{X_n}{n} \right ) \right ] - fx \right | &= \left | \int f \left ( \frac{X_n}{n} \right ) \ d \mathbb{P}(X_n) - \int fx \ d \mathbb{P}(X_n) \right | \\ &= \left | \int f \left ( \frac{X_n}{n} \right ) - fx \ d \mathbb{P}(X_n) \right | \end{align}\]Now we use an extremely useful trick in measure theory! We’ll break up this integral into two parts. One part where the integrand behaves well, and one part (of small measure) where the integrand behaves badly.
Using our intuition that $\frac{X_n}{n} \approx x$, we’ll partition into two parts:
- $\left \lvert \frac{X_n}{n} - x \right \rvert \lt \delta_n$ (the “good” set)
- $\left \lvert \frac{X_n}{n} - x \right \rvert \geq \delta_n$ (the “bad” set)
We’ll be able to control the first part since there our integrand is $\approx 0$, and we’ll be able to control the second part since it doesn’t happen often. Precisely, we’ll use a chernoff bound. There’s a whole zoo of things called “chernoff bounds”, all subtly different, but any one of them will be good enough for our purposes here. I’m just using the first one that came up when I googled “poisson chernoff bounds” :P.
So we split our integral:
\[\begin{align} & \left | \int f \left ( \frac{X_n}{n} \right ) - fx \ d \mathbb{P}(X_n) \right | \\ &\leq \left | \int_{\left | \frac{X_n}{n} - x \right | \lt \delta_n} f \left ( \frac{X_n}{n} \right ) - fx \ d \mathbb{P}(X_n) \right | + \left | \int_{\left | \frac{X_n}{n} - x \right | \geq \delta_n} f \left ( \frac{X_n}{n} \right ) - fx \ d \mathbb{P}(X_n) \right | \\ &\leq \int_{\left | \frac{X_n}{n} - x \right | \lt \delta_n} \left | f \left ( \frac{X_n}{n} \right ) - fx \right | \ d \mathbb{P}(X_n) + \int_{\left | \frac{X_n}{n} - x \right | \geq \delta_n} \left | f \left ( \frac{X_n}{n} \right ) - fx \right | \ d \mathbb{P}(X_n) \end{align}\]Now since $f$ is locally lipschitz, we know that in a neighborhood of $x$, we must have \(|f(y) - f(x)| \leq M_x |y - x|\). So for $\delta_n$ small enough, we’ll have (in the “good” set)
\[\left | f \left ( \frac{X_n}{n} \right ) - fx \right | \leq M_x \left | \frac{X_n}{n} - x \right | \leq M_x \delta_n\]Since $f$ is bounded, say by $\lVert f \rVert_\infty$, we know that no matter what we’ll have
\[\left | f \left ( \frac{X_n}{n} \right ) - fx \right | \leq \left | f \left ( \frac{X_n}{n} \right ) \right | + \left | fx \right | \leq 2 \lVert f \rVert_\infty\]Putting these estimates into the above integral, we find1
\[\begin{align} &\leq \int_{\left | \frac{X_n}{n} - x \right | \lt \delta_n} M_x \delta_n \ d \mathbb{P} + \int_{\left | \frac{X_n}{n} - x \right | \geq \delta_n} 2 \lVert f \rVert_\infty \ d \mathbb{P} \\ &= (M_x \delta_n) \mathbb{P} \left ( \left | \frac{X_n}{n} - x \right | \geq \delta_n \right ) + 2 \lVert f \rVert_\infty \mathbb{P} \left ( \left | \frac{X_n}{n} - x \right | \geq \delta_n \right ) \\ \end{align}\]since we can pull the constants out of the integral, then get the measures of the “good” and “bad” sets.
Now the good set has measure at most $1$2, and chernoff bounds show that the bad set has exponentially small measure:
\[\begin{align} \mathbb{P} \left ( \left | \frac{X_n}{n} - x \right | \geq \delta_n \right ) &= \mathbb{P} \left ( \left | X_n - nx \right | \geq n\delta_n \right ) \\ &\leq 2 \exp \left ( \frac{-(n \delta_n)^2}{2(xn + n \delta_n)} \right ) \\ &= 2 \exp \left ( \frac{-n \delta_n^2}{2(x + \delta_n)} \right ) \end{align}\]So plugging back into our integral, we get
\[\leq M_x \delta_n + 2 \lVert f \rVert_\infty 2 \exp \left ( \frac{-n \delta_n^2}{2(x + \delta_n)} \right )\]We want to show that this goes to $0$, and all we have is control over the sequence $\delta_n$. $M_x$ is a constant, so we have to have $\delta_n \to 0$. Likewise $4 \lVert f \rVert_\infty$ is a constant, so we need $\exp \left ( \frac{-n \delta_n^2}{2(x + \delta_n)} \right ) \to 0$. Since the stuff in the exponent is negative and $2(x + \delta_n) \approx 2x$ is a constant, that roughly means we need $n \delta_n^2 \to \infty$.
We can choose any $\delta_n$ we like which satisfies these two properties, but it’s somewhat difficult to find something that works. We notice that $\delta_n = n^{-\frac{1}{2}}$ just barely fails, since $n^{- \frac{1}{2}} \to 0$, but $n \left ( n^{- \frac{1}{2}} \right )^2 \to 1$.
If we pick $\delta_n$ just a smidge bigger than $n^{- \frac{1}{2}}$, say, $n^{- \frac{1}{2}} \log(n)$, that should get the job done3. Clearly $M_x n^{- \frac{1}{2}} \log(n) = \widetilde{O}\left ( n^{-\frac{1}{2}} \right )$, and moreover
\[\exp \left ( \frac {-n \left ( n^{-\frac{1}{2}}\log(n) \right )^2} {2 \left ( x + n^{-\frac{1}{2}} \log(n) \right )} \right ) = n^{- \frac{1}{2} \frac{1}{\frac{x}{\log(n)} + \frac{1}{\sqrt{n}}}}\]and a tedious L’hospital rule computation shows that this is eventually less than $n^{- \frac{1}{2}} \log(n)$.
So what have we done?
We started with
\[\left | e^{-nx} \sum_{k=0}^\infty \frac{(nx)^k}{k!} f \left ( \frac{k}{n} \right ) - f(x) \right | = \left | \mathbb{E} \left [ f \left ( \frac{X_n}{n} \right ) \right ] - f(x) \right |\]and we showed this is at most
\[M_x \delta_n + 2 \lVert f \rVert_\infty 2 \exp \left ( \frac{-n \delta_n^2}{2(x + \delta_n)} \right ) = O_x \left ( \frac{\log(n)}{\sqrt{n}} \right ) = \widetilde{O}_x \left ( \frac{1}{\sqrt{n}} \right )\]So, overall, we have
\[e^{-nx} \sum_{k=0}^\infty \frac{(nx)^k}{k!} f \left ( \frac{k}{n} \right ) = f(x) \pm \widetilde{O}_x \left ( \frac{1}{\sqrt{n}} \right )\]as promised.
$\lrcorner$
After I got through with this proof, I wanted to see if it agreed with some simple experiments. The last step of this, where we played around with the $\delta_n$s, was really difficult for me, and if your math is making a prediction, it’s a nice sanity check to go ahead and test it.
So then, let’s try to approximate some functions! I’ve precomputed these examples, but you can play around with the code at the bottom if you want to.
First, let’s try to approximate $\sin(3/4)$ using this method. We get nice decay, but it’s much faster than $\frac{\log(n)}{\sqrt{n}}$. Indeed, sage guesses it’s closer to $\frac{\log(n)}{n^{1.6}}$.
(Edit: I realized I never said what these pictures represent. The $x$ axis is the number of terms used, and the $y$ axis is the absolute error in the approximation. You can figure this out based on the code below, but you shouldn’t need to understand the code to understand the graphs so I’m adding this little update ^_^.)
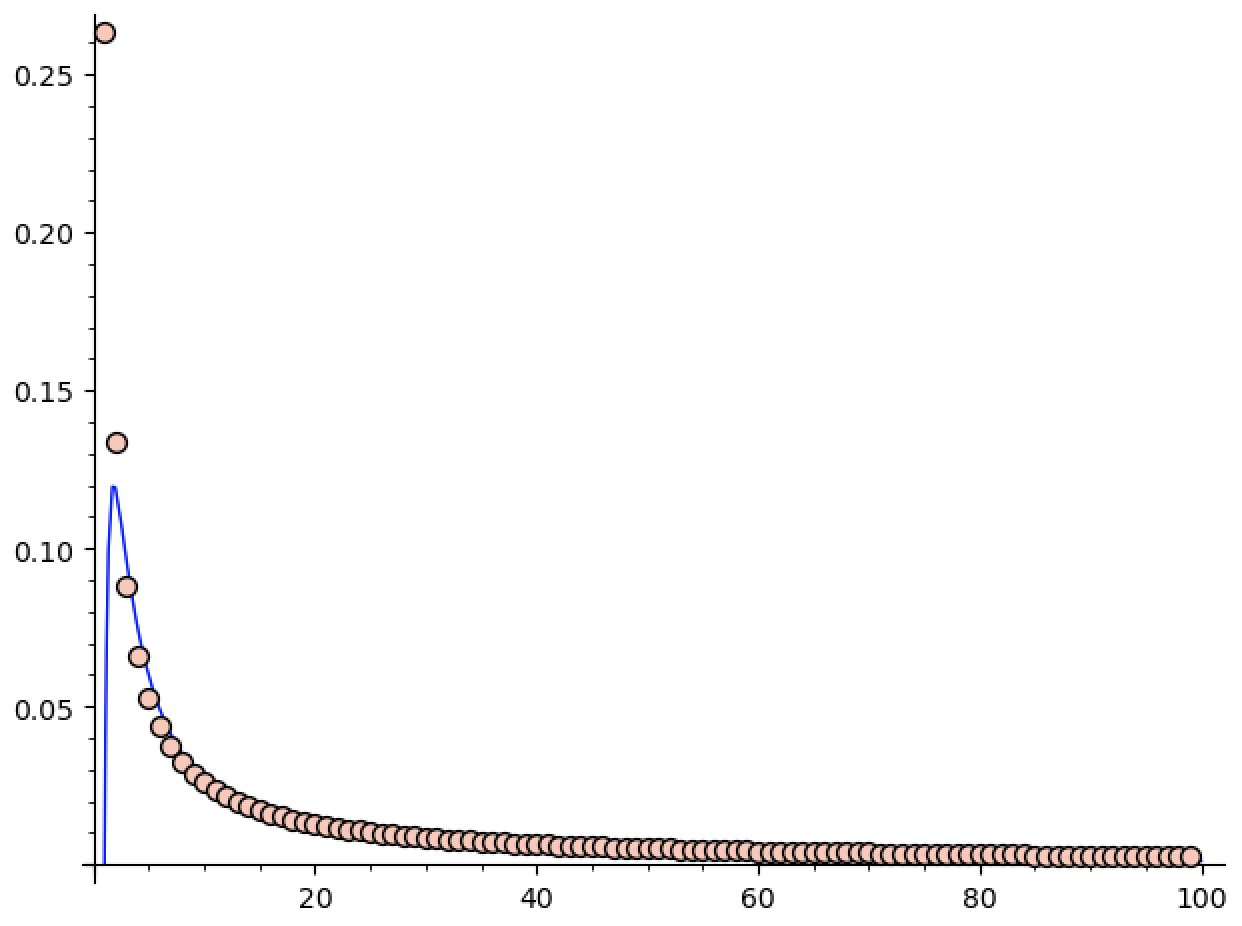
That’s fine, though. It’s more than possible that I was sloppy in this derivation, or that tighter error bounds are possible (especially because $\sin$ is much better behaved than your average bounded locally lipschitz function).
So let’s try it on a more difficult function4. What if we try to approximate $\sin(1/(0.001 + x))$ at $x = 0.1$. (We have to perturb things a little bit so the code doesn’t divide by $0$ anywhere).
Now we get some oscillatory behavior, which seems to be stabilizing.
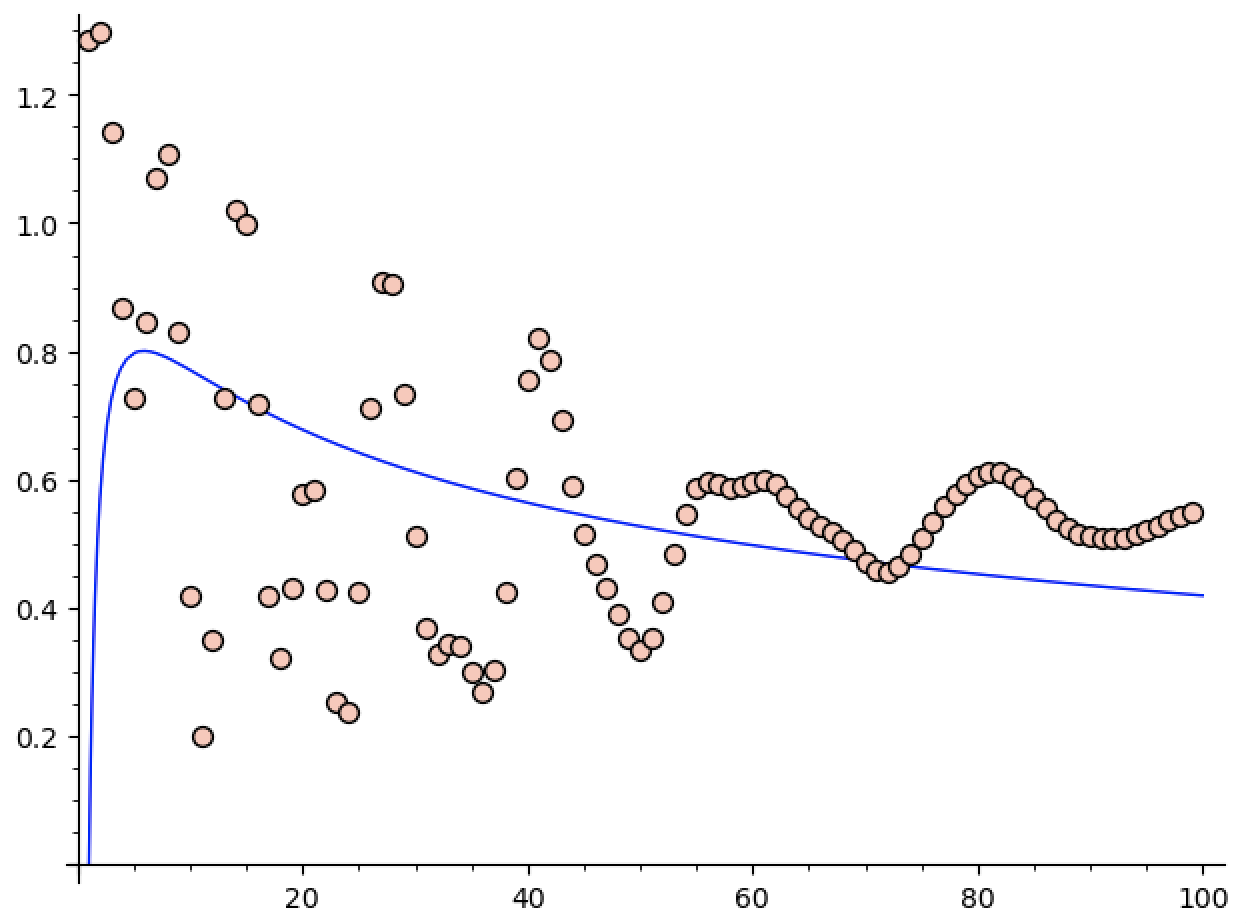
At least the guess in this case is closer to what we computed, as the blue graph is roughly $1.23 \frac{\log n}{n^{0.56}}$. This obviously isn’t an upper bound for our data, but it’s only off by a translation upwards, and they do seem to be decaying at roughly the same rate.
The fact that this example gives something fairly close to the bounds we ended up getting makes me feel better about things. In fact, after a bit of playing around, I can’t find anything where sage guesses the decay is slower than $\frac{\log(n)}{\sqrt{n}}$, which also bodes well.
If you want to play around for yourself, I’ve left the sage code below!
I’m pretty confident in what we’ve done today, but I can’t help but feel like there’s a better way, or that there’s slightly tighter bounds to be had. If there’s anyone particularly skilled in “hard” analysis reading this, I would love to hear your thoughts ^_^.
In any case, this has been fun to work through! I’ll see you all soon!
-
In the interest of continuing the quick analysis trick tradition of saying the obvious thing, notice what we’ve done here. We want to control an integral. How do we do it?
We break it up into a “good” piece, which is big, and a “bad” piece, which is small.
The “good” piece we can control because it’s good. For us, this means $f \left ( \frac{X_n}{n} \right ) \approx f(x)$, so their difference is $\approx 0$.
The “bad” piece we can’t control in this way. Indeed it’s defined to be the piece that we can’t control in this way. Thankfully, if all is right with the world, the “bad” piece will be small! So we get some crummy (uniform) estimate on the bad piece, and then multiply by the size of the piece. Since the size is going to $0$ and our bound is uniform (even if it’s bad), we’ll win! ↩
-
Notice just like we were content with a crummy bound on the integrand of the bad piece because we’re controlling the measure, we’re content with a potentially crummy bound on the measure of the good piece because we’re controlling the integrand!
Of course, for our particular case, $1$ is actually a fairly good bound for the measure of the good piece, but we don’t need it to be. ↩
-
In fact, $\delta_n = n^{- \frac{1}{2} + \epsilon}$ also gets the job done, but the computation showing
\[\exp \left ( \frac{-n \delta_n^2}{2(x + \delta_n)} \right ) = O(\delta_n)\]is horrendous. ↩
-
Interestingly, while trying to break things, I realized that I don’t really have a good understanding of “pathological” bounded lipschitz functions. Really the only tool in my belt is to make things highly oscillatory…
Obviously we won’t have anything too pathological. After all, every (globally) lipschitz function is differentiable almost everywhere, and boundedness means we can’t just throw singularities around to cause havoc. But is oscillation really the only pathology left? It feels like there should be grosser things around, but it might be that they’re just hard to write down.
Again, if you have any ideas about this, I would also love to hear about it! ↩