A New (to me) Perspective on Jordan Canonical Form
01 Feb 2022
Lie Algebras have been on my to-learn list for a fairly long time now, and I’m finally taking a class focusing on them (and their representation theory). Our professor is very concrete in how she presents things, and so this class is doubling as a higher level review of some matrix algebra, which I’ve been enjoying. In particular, last week we talked about the Jordan Canonical Form in a way that I quite liked, and which I’d never seen before. I’m sure this will be familiar to plenty of people, but I want to write up a thing about it anyways just in case!
Now then, what is JCF?
Not every matrix can be diagonalized, so it’s natural to ask if there’s a “next best thing”. The answer is “yes”, and it’s the JCF1. When a matrix is diagonal it means that it acts just by rescaling along some axes, given by the basis we use to diagonalize it. The JCF lets us write any matrix2 as a diagonal matrix, plus a few $1$s right above the diagonal. Stealing wikipedia’s example, we see that
\[\begin{pmatrix} 5 & 4 & 2 & 1 \\ 0 & 1 & -1 & -1 \\ -1 & -1 & 3 & 0 \\ 1 & 1 & -1 & 2 \end{pmatrix}\]can be “almost diagonalized” as
\[\begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \\ 0 & 0 & 4 & 1 \\ 0 & 0 & 0 & 4 \end{pmatrix}\]Notice this is diagonal except for $1$s immediately above the diagonal. Moreover, the $1$ lies “between” the repeated $4$s. This is typical, in the sense that any matrix $M$ can be brought into the following form3:
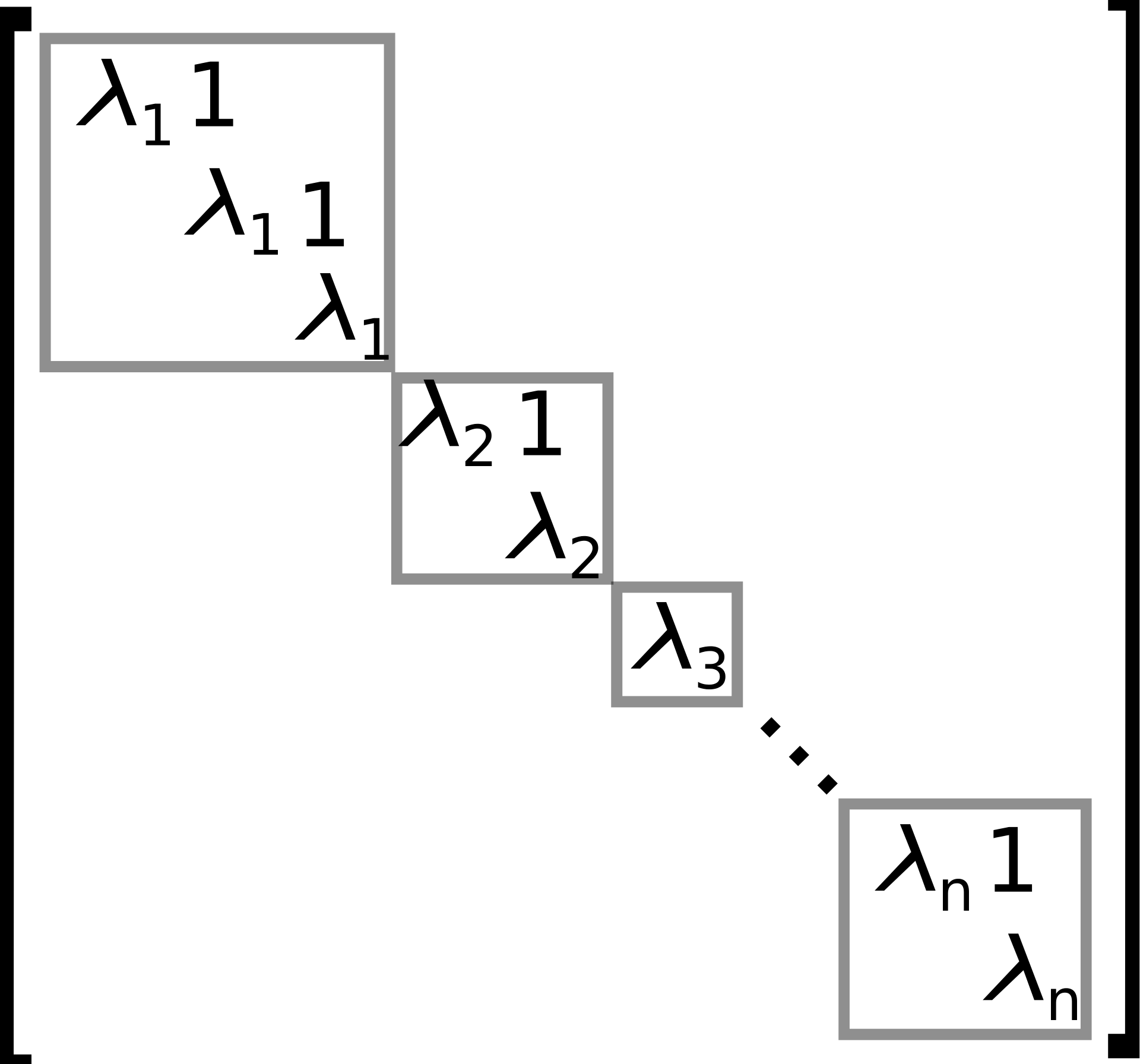
where the $\lambda_k$ are eigenvalues of $M$, possibly with repetition.
This says, roughly, that we can decompose our space into disjoint subspaces. Then $M$ acts on each subspace by a “scale and shift” action, where we send \(\vec{v}_{k+1}\) to \(\lambda \vec{v}_{k+1} + \vec{v}_k\). The top basis vector, \(\vec{v}_0\), just gets rescaled: \(M \vec{v}_0 = \lambda \vec{v}_0\).
Then a matrix is diagonalizable if and only if each of these subspaces is one dimensional (do you see why?).
One reason to care about this is classification. If we pick some reasonable convention for ordering the eigenvalues, then every matrix has a unique JCF, and two matrices are similar if and only if they have the same JCF. This lets us solve the similarity problem in polynomial time4, which is quite nice.
Another reason is for computation. When working with matrices (by hand or by computer) it’s nice to have a lot of $0$s hanging around, because it makes computation easier. Moreover, we can make special use of the form of a matrix in JCF in order to do computations we wouldn’t be able to do at all in general. For instance, can you see what $M^2$ and $M^3$ must look like for a matrix in JCF? Obviously this is hopeless for an arbitrary matrix.
These computational benefits help us solve real problems, for instance it’s comparatively easy to compute matrix exponentials when $M$ is in JCF, and this lets us solve coupled differential equations. See here, say.
Now for the new perspective:
The entire point of JCF is to find a basis which renders our favorite linear transformation particularly easy to study. So it never crossed my mind to look into basis-agnostic formulation of the theorem. Of course, it’s almost always natural to ask if there’s a version of a theorem that doesn’t rely on a choice of basis, and (surprisingly, imo) there is actually such a formulation for the JCF!
So what’s the idea?
If we allow ourselves to use addition as well as multiplication, than the JCF says that there’s a basis which makes $T$ look like the sum of a diagonal matrix and a (particularly sparse) strictly upper triangular matrix.
In the example from before, we write
\[\begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \\ 0 & 0 & 4 & 1 \\ 0 & 0 & 0 & 4 \end{pmatrix} = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \\ 0 & 0 & 4 & 0 \\ 0 & 0 & 0 & 4 \end{pmatrix} + \begin{pmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{pmatrix}\]Another way to say this is that every linear map on $\mathbb{C}^n$ decomposes as the sum of two commuting maps5, one of which is semisimple one of which is nilpotent:
\[T = T_s + T_n\]It’s clear that the latter matrix is nilpotent (after all, it’s strictly upper triangular) and that nilpotent-ness is a condition which doesn’t rely on a choice of basis.
Some meditation shows that semisimplicity corresponds exactly to diagonalizability. The following famous example should help guide your meditation. In this context we should view it as a $2 \times 2$ Jordan block:
\[\begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}\]Notice there is an invariant subspace which is not complemented. Namely the space \(\left \{ \begin{pmatrix} a \\ 0 \end{pmatrix} \ \middle | \ a \in \mathbb{C} \right \}\).
Of course, semisimplicity is a much trickier notion to come up with compared to nilpotency. But once you’ve seen it it’s clear that it’s also basis-agnostic.
So the whole decomposition doesn’t depend on a choice of basis6! This makes it much more amenable to generalization, and in fact it does go through in a wide variety of settings where we don’t directly have access to JCF7. See the Jordan-Chevalley Decomposition.
-
When I was taking my first ever linear algebra class (which, incidentally, was also my first proof based class) as a freshman, our professor (Pisztora) spent the last few weeks giving a completely algorithmic way to get our hands on the JCF of a matrix.
Later in life, I learned about the fundamental theorem of fintely generated modules over PIDs (which really needs a snappier name). It gives us two canonical ways to decompose a fg PID-module: the Primary Decomposition and the Invariant Factor Decomposition.
Now if we view $\mathbb{C}^n$ as a $\mathbb{C}[x]$ module where $x$ acts by some linear transformation $T$, this theorem tells us we can decompose $\mathbb{C}^n$ into subspaces where $T$ acts in a particularly simple way.
The primary decomposition of $\mathbb{C}^n$ provides a basis on which $T$ attains its Jordan Canonical Form, and the invariant factor decomposition provides a basis on which $T$ is in Rational Canonical Form (which, incidentally, I like more. But that might be because it was a big part of my undergraduate research).
I won’t say more about the existence proofs here, because that’s not really the point of the post. ↩
-
Over an algebraically closed field ↩
-
This image, like the previous example, was stolen from wikipedia ↩
-
Where we gloss over some subtle details of the complexity of working with exact complex numbers. ↩
-
It wasn’t immediately clear to me that these maps commute, but (as is often the case) it’s pretty obvious in hindsight. If it’s not clear to you, you should take some time and work through it!
As a hint, it suffices to check commutativity in each Jordan block. But of course, within each block, the diagonal matrix is particularly simple… ↩
-
In fact, there’s a ~ bonus property ~ as well, which says that $T_s$ and $T_n$ are actually polynomials in $T$!
I’m still too new to this to have a concrete application in mind, but it’s an extremely cool fact which seems obviously useful on an intuitive level. ↩
-
Though, as a quick exercise, you might wonder if this goes through for linear maps on an infinite dimensional vector space.
I have a counterexample in mind, though I don’t actually have a formal proof that it has no such decomposition.