Is a Random Perfect Group Nontrivial?
20 Mar 2026 - Tags: sage
So it’s finals season, and earlier today some of the younger grad students were asking me for help studying for their topology finals. One of their practice problems was to build a cell complex with one 0-cell, two 1-cells, and two 2-cells which has nontrivial $\pi_1$ but trivial $H_1$. In principle, this isn’t very hard to do – I encourage you to think about it for a while to see what kind of group you’re looking for… Then see if you can look in the literature for a source of such a group.
Last chance to think about it yourself…
Ok, the fact that we have two 1-cells means our fundamental group will have two generators, say $a$ and $b$. Then the two 2-cells will give us two relations, say $R$ and $S$. Since we know that $H_1$ is the abelianization of $\pi_1$, this means we’re looking for a perfect group with a presentation by two generators and two relations.
If you try to build one by hand for a while (and I encourage you to try!), it’s actually somewhat difficult to do! I ended up looking up “small presentations of perfect groups” (or something like this) and quickly found Campbell, Kawamata, Miyamoto, Robertson, and Williams’s Deficiency Zero Presentations for Certain Perfect Groups which is full of examples1. I also posted about this on mastodon, and Omar Antolín had a characteristically helpful response! He mentioned that the binary icosahedral group gets the job done2, and these relations are the kind of thing you have a chance of finding by hand!
This brings up an interesting question, though – In some sense you would expect that two “random” relations should get the job done… Obviously things can’t be completely random, since we need the abelianized relations to be a matrix with determinant $\pm 1$ – otherwise our $H_1$ will have torsion… But what if we condition on this property. Does a “random” pair of relations work?
It’s been a minute since I’ve written a genuinely short blog post, and I was curious enough to write up some sage code anyways3, so I thought it could be fun to do it together!
As a quick exercise: What do I mean when I say that “we need the abelianized relations to be a matrix with determinant $\pm 1$ – otherwise our $H_1$ will have torsion”?
Ok, so here’s the plan:
We’ll take as input a number $N$. Then we’ll iterate through all pairs of relations $R,S$ which are words in the alphabet \(\{a, a^{-1}, b, b^{-1} \}\) of length $N$ then we’ll see what fraction of those with vanishing $H_1$ also have nonvanishing $\pi_1$. If our conjecture is right then this fraction should get closer to $1$ as $N$ gets bigger.
Let’s do it!
This basically does exactly what you expect, haha. The main things to
take note of are the @fork decorator when checking if a group is trivial.
Since this is undecidable in general we bail on the computation if it
lasts longer than thirty seconds… This creates some serious overhead on
each loop, which is basically the same overhead involved in parallelising…
So we might as well parallelise! This is what the @parallel decorator does.
My laptop only has a measly 8 cores, so that’s how many I tell it to use.
The reseed_rng flag is to make sure each process gets its own RNG, otherwise
our 10,000 “random” runs will all be the same!
So what does the final scatter plot look like?
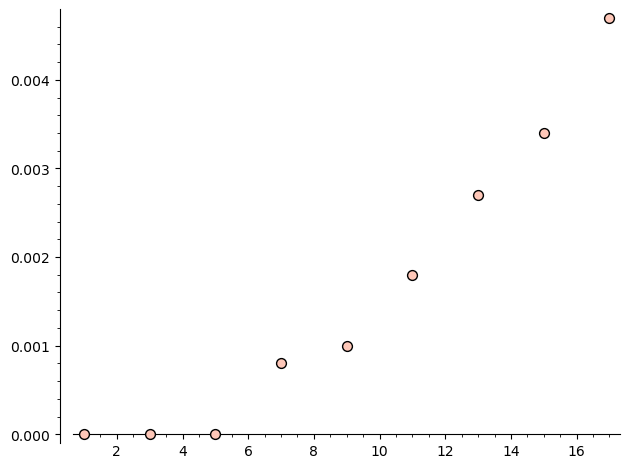
The trend is definitely upwards, which makes sense. Interestingly the code only starts seeing examples once the relations have length $7$. The smallest example I’m aware of is the binary icosahedral group that Omar told me about, which happens to have two relations of length $7$!
Even with relations of length $17$, though, only a tiny $0.4\%$ of the samples with trivial $H_1$ had an interesting $\pi_1$… I still think that this ratio should approach $1$ as the size of the relations gets large? But I was really hoping this data would be more suggestive, haha. That said, there’s a lot of problems with the data!
My laptop starts to struggle after $N=8$, which corresponds to relations of length $17$. I’ve uploaded the raw output if you’re interested in looking at it, but the main thing to note is how often we bail on computations. This is almost certainly throwing off our statistics, but I don’t really know how. After all, we’re now conditioning on both “trivial $H_1$” and “can be checked to be (non)trivial in at most 30 seconds on my ten year old laptop”. Here’s a table:
| Relation Length | Nontrivial $\pi_1$ | Total Runs | Killed Computations |
|---|---|---|---|
| 1 | 0 | 10000 | 0 |
| 3 | 0 | 10000 | 0 |
| 5 | 0 | 10000 | 0 |
| 7 | 8 | 10000 | 0 |
| 9 | 10 | 10000 | 2 |
| 11 | 18 | 10000 | 19 |
| 13 | 27 | 10000 | 183 |
| 15 | 34 | 9998 | 664 |
| 17 | 47 | 9995 | 1726 |
So at this point the possible error we’re incurring by killing computations that take longer than $30$ seconds is dwarfing the number of groups we’re able to quickly prove are (non)trivial. Plus when we kill computations there seems to be a small chance that GAP throws some kind of exception that I’m not sure how to handle… This is the reason some later runs have slightly fewer than $10,000$ trials. I thought about increasing the timeout to a minute, or even five minutes, and running it again overnight to see if we can push things a bit further? But I decided I don’t really care, haha. I’m supposed to be writing a thesis, after all.
Further optimizing this would make a great project for somebody else to try, though! I think that it should be quite easy to get better data, and a lot of it! If you decide to look into this, definitely reach out and let me know what you find ^_^. In that vein, here’s a few take-home problems that you might want to play around with. They all look fun (at least to me) and if I had the time to spend I would probably think about them for a few weeks.
Can you further optimize this code to get more data? There’s a few obvious things to try:
- writing in pure GAP, rather than a python package
- somehow checking triviality without computing the cardinality of a nontrivial group
- have a better computer than me, with lots of cores for parallel computation
You might have noticed that all our trials were on odd relation lengths… Experimentally it looks like even relation lengths never give perfect groups!
It’s pretty easy to prove that this really is the case. I’ll include a quick proof in a spoiler tag, but you might want to play around with it yourself for a minute.
solution
We know there's $2n$ many letters in each of the relations $R$ and $S$, coming from the alphabet $\{a,A,b,B\}$. We'll write $R_a$ for the number of times $a$ shows up in $R$, and similarly for $S_B$, etc. Then working mod $2$ we have $$R_a + R_A + R_b + R_B = 2n \equiv_2 0$$ so that (remembering that $+$ and $-$ are the same mod $2$) $$R_a - R_A \equiv_2 R_b - R_B$$ Recall that the abelianization of $G = \langle a,b \mid R, S \rangle$ vanishes if and only if the following matrix has determinant $\pm 1$: $$ \begin{pmatrix} R_a - R_A & S_a - S_A \\ R_b - R_B & S_b - S_B \end{pmatrix} $$ but working mod $2$ again and using the above observation say that $R_a - R_A \equiv_2 x \equiv_2 R_b - R_B$ and $S_a - S_A \equiv_2 y \equiv_2 S_b - S_B$. Then the mod-2 determinant of the above matrix is $xy - xy = 0$ so that this matrix can never have determinant $\pm 1$!For a harder problem, which I don’t know how to solve, you might ask if the fraction of presentations with nontrivial $\pi_1$ approaches $1$ at all! Or even better, you might ask what the asymptotic behavior is as the number of relations gets large!
I asked about this on mathoverflow today, and I’m very excited to see what people have to say! I really don’t know much combinatorial group theory, so no matter what the conversation turns into I’m quite likely to learn something.
Alright! This is my first really short blog post in… quite a while, haha. I wrote the code pretty quickly, and once I figured out how to get the long computation to time out properly (and let it run all evening yesterday) the rest of the post came together in like two hours. I love problems like this, so it was easy to get nerdsniped by it.
Now it’s back to checking some details for my thesis. Next week is spring break, so I’m hoping to really sit down and get a lot done before teaching starts back up.
OH! And that reminds me! I mentioned this in a draft for a blog post on representation theory in analysis, but I haven’t mentioned it anywhere that’s live yet, so I should say it here! I got a postdoc!! 🎉🎉
This Fall I’ll be going to Montana State University to work with Sam Gunningham, David Ayala, and probably Ryan Grady too. I’ll be thinking about all sorts of fun things like factorization homology, “quantum” geometric langlands, topological field theories, and more! Everyone at the MSU campus has been so nice to me, and even though I’m an island girlie through and through I’m oddly excited to experience real winter for the first time in my life, haha. I’m tearing up a little bit writing this because I’m so happy to get to go there and work with them.
Alright, thanks for reading everyone! It’s back to the dissertation grind now, but this was really fun to think about for a day or two.
Stay safe, and we’ll talk soon 💖
-
As an aside, this search also pulled up Bray, Conder, Leedham-Green, and O’Brien’s Short presentations for alternating and symmetric groups which shows how to get presentations for alternating and symmetric groups with 2 generators and $\mathsf{PolyLog(n)}$ many relations (at least that’s my understanding – I haven’t read this paper closely at all).
This really scratches some kind of asymptotic computer science itch in my brain! ↩
-
He also mentioned he knows about this group because it’s the fundamental group of the Poincaré homology sphere! This makes it especially reasonable that he might have thought of it, since the original context for this problem is about a cell complex with $\pi_1$ but no $H_1$, and that’s exactly (one of) the defining properties of the homology sphere! ↩
-
Checking if a presentation gives the trivial group is famously impossible, but since we’re restricting ourselves to two generators and two relations I’m hopeful that sage can handle these cases for us! ↩